1. Introduction
In previous post, we covered the basics of LSP and how we can use C#-LSP to implement a language server that can communicate with a language client using LSP. The server had basic code to be able to receive and track changes to all buffers of the project through BufferManager. It can be very tricky to design programs that work with completely free flowing text. The resulting programs would also be very brittle. Hence we impose a certain structure on the text which makes it easier for us to write programs. JSON is one such structure which is used to write ARM templates. These structures are generally defined and described using a grammar. You can read this wikipedia entry for more information on programming language grammars. To make it easier and efficient for programs to understand and interpret the text in accordance with a grammar, we define lexers and parsers. The process of using a parser to interpret text is called parsing. In this article, we will use a parser for JSON language to parse ARM templates and do basic error checking. To follow along, checkout commit b794cd3 from Armls repository which has the changes described in this article.
2. TreeSitter
From the official documentation at https://tree-sitter.github.io/tree-sitter/
Tree-sitter is a parser generator tool and an incremental parsing library. It can build a concrete syntax tree for a source file and efficiently update the syntax tree as the source file is edited.
In other words, given the grammar of JSON language, TreeSitter can generate a parser for us that can (incrementally) parse JSON files. We won't be using the incremental parsing functionalities of TreeSitter in this series as we are asking for complete changed file from the language client. Another important feature of TreeSitter is that the parsers generated by TreeSitter are fault tolerant, i.e., the parser can recover from syntax errors in file and continue to parse the rest of the (valid) file according to the rules of the grammar. We will use TreeSitter to create concrete syntax trees for all files in the project. These trees are useful for all sorts of functionalities, like syntax checking, finding definitions and references, etc. TreeSitter is not the only parsing library out there, however, it is probably the most popular one. You can choose any parsing library that fits your needs (or write your own too), but it must be fault-tolerant to be able to identify all issues in a file in a single pass. Core API of TreeSitter is designed to work with an abstract concept of TSLanguage. Any language that provides a valid implementation of this structure can work with the library. For our usecase, we want to work with tree-sitter (GitHub) and tree-sitter-json (GitHub) repositories. Both come with a Makefile to easily generate a linkable library. Compilation on Windows might require MSYS2 and MinGW.
NOTE: Thoroughly covering the concepts of parsing is beyond the scope of this article. One can find various resources online that explain the concepts in various levels of depth. My AI agent says that Chapters 4-6 from the book Crafting Interpreters give an approachable introduction to the concepts of lexing and parsing.
2.1. C# Bindings
TreeSitter is a library written in pure C. To use TreeSitter with our language server written in C#, we need some sort of Foreign Function Invocation(FFI) feature. Thankfully C#, like all major high level languages, comes with the ability to interface with C libraries out of the box (P/Invoke). While one can directly call C functions from C# code, this becomes very verbose and awkward because of different design philosophies of 2 languages, C# being an object oriented language and C being a purely imperative one. Programmers generally rely on language bindings to effectively utilize features of systems outside of their choice of language. Language bindings expose the functionalities of outside system in a way that is consistent and idiomatic for the language you are working in. In this case, functionalities of C TreeSitter library, which works with structures and functions, will be exposed in a way that is idiomatic in C#, which is through classes and methods. TreeSitter homepage links the official bindings for various languages, including C#. However, the linked C# bindings are outdated and only designed to be compiled on Windows. We will write our own bindings to work around this limitation. This will allow our code to be written in such a way that it will work on all platforms that are supported by C# and TreeSitter. I have written a set of bindings for all required structures and methods for parsing and basic error checking in TreeSitter package in Armls. I encourage you to browse through the bindings to get an idea of different types of functionalities implemented. To get a deeper idea of the C functions used in the bindings, look at the definition of that TreeSitter API in api.h which I have checked in the repository for convenience.
3. Writing Bindings
The repository contains a set of bindings to interface with many constructs of TreeSitter. I will cover the concepts of writing C bindings in C# using the class TSQueryCursor.cs as it is short but touches virtually all of the required concepts.
using System.Runtime.InteropServices;
namespace Armls.TreeSitter;
public class TSQueryCursor
{
internal readonly IntPtr cursor;
internal TSQueryCursor(IntPtr cursor)
{
this.cursor = cursor;
}
C is an imperative language that keeps the state and behaviors separate. Unlike OOP languages, the state lives in a struct while the behavior lives in a function independent of the struct. This requires us to pass the state explicitly to all functions, either through function parameters or through global variables. Virtually all methods in TreeSitter take in the state as the first parameter. In C#, generally the state is encapsulated and maintained by the objects themselves. Hence we are going to declare a pointer (IntPtr) to a cursor coming from C library as an instance variable in the class.
[DllImport(
"/Users/samvidmistry/projects/lsp/armls/tree-sitter/libtree-sitter.dylib",
CallingConvention = CallingConvention.Cdecl
)]
private static extern bool ts_query_cursor_next_capture(
IntPtr cursor,
ref TSQueryMatchNative match,
out uint capture_index
);
Next we need to declare the signature of the native method that our class can invoke. We first use DllImport attribute on the method declaration to specify which dynamically linked library will provide an implementation for this function. We also specify the Calling Convention for the function, which just a set of rules around how to pass values to and receive values from unmanaged code. Next we declare the signature of the method. The method is defined as static to declare that these methods are not associated with any instance of this class and marked as extern to declare that the implementation for this method will be provided by some externally linked source. First parameter is an IntPtr, a signed integer value that has the same bit-width as a pointer, i.e., an IntPtr can be used to store and pass pointers to methods. Next we see ref keyword for second parameter. ref is a safe way to pass pointers to managed structures to unmanaged code. Their values can flow into unmanaged code and any changes to the value also reflect out into managed code. out works in the same way as ref except that changes can only flow out of unmanaged code to managed code. So there is no strict need to initialize this variable with any value in managed code.
public bool Next(out TSQueryMatch? match)
{
TSQueryMatchNative matchNative = new();
uint captureIndex = 0;
if (ts_query_cursor_next_capture(cursor, ref matchNative, out captureIndex))
{
match = new TSQueryMatch(matchNative);
return match.match.capture_count > 0;
}
match = null;
return false;
}
}Finally, we expose an idiomatic C# method on the class equivalent to the native function we intend to call in that method. You call the native function in your method, marshaling and unmarshaling the requests and responses so that any of the values being returned from the method are also valid C# objects. This knowledge should empower you to be able to read any of the bindings implemented in TreeSitter package. Moving forward in this article and series, I will directly use the C# bindings to work with the syntax trees without showing the underlying binding. I will cover the technicalities of the library C functions as and when needed.
4. Syntax Checking
4.1. Parsing
The most basic thing you can do using a parser for any language is to check if the provided text conforms to the grammar for that language. This is also referred to as Syntax Checking. TreeSitter API is designed to work independently from the language it is working with. The core logic of walking and manipulating the syntax trees lives in the TreeSitter repository, while mapping TreeSitter concepts to constructs in any particular language is outsourced to parsers generated from grammars. Generated parsers provide an implementation of TSLanguage struct which the rest of the code in TreeSitter works with in language independent way.
NOTE: I've omitted some details in the snippets like error handling and extern declarations. Look at the source files in GitHub repository for complete implementations.
In our case, we are working with JSON so let's first create a language class for JSON.
public static class TSJsonLanguage
{
// ... extern declarations
public static IntPtr Language()
{
return tree_sitter_json();
}
}
This is a simple wrapper over the C function tree_sitter_json() provided by tree-sitter-json library to make it C#-like. TreeSitter Parser returns a TSTree of the parsed text that can be maniupated. So let's create a wrapper for that.
public class TSTree
{
IntPtr tree;
// ... extern declarations
public TSTree(IntPtr tree)
{
this.tree = tree;
}
public TSNode RootNode()
{
return new TSNode(ts_tree_root_node(tree));
}
}
Now a TSTree consists of a set of TSNode structs representing nodes in the concrete syntax tree of parsed text. Let's create a wrapper for that.
[StructLayout(LayoutKind.Sequential)]
internal struct TSNodeNative
{
[MarshalAs(UnmanagedType.ByValArray, SizeConst = 4)]
public uint[] context;
public IntPtr id;
public IntPtr tree;
}We need a C# struct to represent the C struct needed to pass in various TreeSitter methods as state. C# allows methods to be added directly to this struct as well but we don't want the users of our package to manipulate the state for unmanaged code directly, so we will put another class wrapper over this native struct and expose sensible and safe methods.
public class TSNode
{
internal readonly TSNodeNative node;
// ... extern declarations
internal TSNode(TSNodeNative nativeNode)
{
node = nativeNode;
}
public OmniSharp.Extensions.LanguageServer.Protocol.Models.Range GetRange()
{
var start = ts_node_start_point(node);
var end = ts_node_end_point(node);
return new OmniSharp.Extensions.LanguageServer.Protocol.Models.Range(
new OmniSharp.Extensions.LanguageServer.Protocol.Models.Position(
(int)start.row,
(int)start.column
),
new OmniSharp.Extensions.LanguageServer.Protocol.Models.Position(
(int)end.row,
(int)end.column
)
);
}
}
The TSNode wrapper simply wraps a TSNodeNative struct and provides a convenience method to convert the bounds of a TSNodeNative to Range LSP type. Finally, we are ready to define a wrapper for the parser.
public class TSParser
{
private IntPtr parser;
// ... extern declarations
public TSParser(IntPtr language)
{
parser = ts_parser_new();
bool success = ts_parser_set_language(parser, language);
}
public TSTree ParseString(string text)
{
var (nativeText, length) = Utils.GetUnmanagedUTF8String(text);
return new TSTree(
ts_parser_parse_string_encoding(
parser,
IntPtr.Zero,
nativeText,
length,
TSInputEncoding.TSInputEncodingUTF8
)
);
}
}
TSParser simply takes a pointer to a TSLanguage, creates an instance of native parser struct and sets the language on it. It exposes a method to parse a string using the language used to construct the parser and returns a TSTree instance, holding the syntax tree of the parsed text.
4.2. Finding Errors
Whenever TreeSitter runs into a node that is faulty as per the definition of the grammar, it flags that position and the surrounding faulty area by adding an (ERROR) node in the tree. We can find these error nodes and give their bounds to the language client to highlight syntax errors in the editor. To find a node with any particular structure, we need to walk the tree. Let's create some classes and bindings for tree traversal. TreeSitter uses a query language that describes the structure to match in Lisp notation. When a query is executed on a tree, it returns a mutable cursor struct that stores the relevant state for that search. You can incrementally advance this cursor to iterate through all matches. A query can have zero or more captures. A capture, just like regular expressions, binds to the text associated with a matched node. With that terminology out of the way, let's create bindings for a query match. This is what we will get from the cursor as it walks the tree finding nodes which match the query pattern.
[StructLayout(LayoutKind.Sequential)]
internal struct TSQueryMatchNative
{
public uint id;
public ushort pattern_index;
public ushort capture_count;
public IntPtr captures; // Pointer to TSQueryCapture array
}
[StructLayout(LayoutKind.Sequential)]
internal struct TSQueryCaptureNative
{
public TSNodeNative node;
public uint index;
}
public class TSQueryMatch
{
internal readonly TSQueryMatchNative match;
internal TSQueryMatch(IntPtr queryMatchPtr)
{
match = Marshal.PtrToStructure<TSQueryMatchNative>(queryMatchPtr);
}
internal TSQueryMatch(TSQueryMatchNative nativeMatch)
{
match = nativeMatch;
}
public ICollection<TSNode> Captures()
{
var capturesList = new List<TSNode>();
var count = match.capture_count;
var capturesPtr = match.captures;
int size = Marshal.SizeOf<TSQueryCaptureNative>();
for (int i = 0; i < count; i++)
{
var capturePtr = IntPtr.Add(capturesPtr, i * size);
var nativeCapture = Marshal.PtrToStructure<TSQueryCaptureNative>(capturePtr);
capturesList.Add(new TSNode(nativeCapture.node));
}
return capturesList;
}
}
Above code defines a couple of internal C# structs to correspond to C structs from the library. TSQueryMatchNative describes a match struct and TSQueryCaptureNative describes a particular capture within the query match. We expose a straightforward Captures() method from the C# wrapper which returns a collection of nodes, one corresponding to each capture.
NOTE: Returning an ICollection from Captures() is not ideal. ICollection is not indexable. This makes it impossible to find out which item in the collection matches which capture. IList would have been better. It works fine for now because we are capturing a single item in our query but we will have to update it in the future if we search for a query with multiple captures.
Definition of TSQueryMatch makes it very straightforward to define a TSQueryCursor which just iterates over the native cursor objects and returns the matches.
public class TSQueryCursor
{
internal readonly IntPtr cursor;
// ... extern declarations
internal TSQueryCursor(IntPtr cursor)
{
this.cursor = cursor;
}
public bool Next(out TSQueryMatch? match)
{
TSQueryMatchNative matchNative = new();
uint captureIndex = 0;
if (ts_query_cursor_next_capture(cursor, ref matchNative, out captureIndex))
{
match = new TSQueryMatch(matchNative);
return match.match.capture_count > 0;
}
match = null;
return false;
}
}
We expose a method Next which iterates over the matches, binds a match to the out parameter to be consumed and returns false when it runs out of matches. This method makes it very convenient to consume results in a while loop. Finally we can define TSQuery which simply takes a query and a language and executes the query on a node, returning the cursor for iteration over matches.
public class TSQuery
{
private IntPtr query;
// ... extern declarations
public TSQuery(string queryString, IntPtr language)
{
var (nativeQuery, length) = Utils.GetUnmanagedUTF8String(queryString);
uint errorOffset;
int errorType;
query = ts_query_new(language, nativeQuery, length, out errorOffset, out errorType);
}
public TSQueryCursor Execute(TSNode node)
{
var cursor = new TSQueryCursor(ts_query_cursor_new());
ts_query_cursor_exec(cursor.cursor, query, node.node);
return cursor;
}
}4.3. Putting it all together
Now that we know how to parse text files into syntax trees and how to walk a syntax tree to find nodes matching a query, we can
- Parse an ARM template
- Query for errors
- Walk the tree with a cursor
- Publish the locations of
(ERROR)nodes to language client for highlighting in editor
4.3.1. Analyzer
Let's create an Analyzer class that will analyze our buffers. Syntax checking is only one kind of analysis that we can do on a buffer. We can add more and more analyses like looking for missing variables, looking for missing resources, providing linting warnings and highlighting best practices, etc. All of it can be added to the analyzer, which will return a collection of diagnostics that the editor can highlight, simplifying our sync handler.
public class Analyzer
{
private readonly TSQuery errorQuery;
public Analyzer(TSQuery errorQuery)
{
this.errorQuery = errorQuery;
}
public IDictionary<string, IEnumerable<Diagnostic>> Analyze(
IReadOnlyDictionary<string, Buffer.Buffer> buffers
)
{
return buffers
.Select(kvp => new KeyValuePair<string, IEnumerable<Diagnostic>>(
kvp.Key,
AnalyzeBuffer(kvp.Value)
))
.ToDictionary(kvp => kvp.Key, kvp => kvp.Value);
}
private IEnumerable<Diagnostic> AnalyzeBuffer(Buffer.Buffer buf)
{
IEnumerable<Diagnostic> diagnostics = new List<Diagnostic>();
var cursor = errorQuery.Execute(buf.ConcreteTree.RootNode());
while (cursor.Next(out TSQueryMatch? match))
{
diagnostics = match!
.Captures()
.Select(n => new Diagnostic()
{
Range = n.GetRange(),
Severity = DiagnosticSeverity.Error,
Source = "armls",
Message = "Syntax error",
})
.Concat(diagnostics);
}
return diagnostics;
}
}
Analyzer simply takes a dictionary of buffers and analyzes them. Corresponding to each buffer, it produces a collection of diagnostics.
4.3.2. Sync Handler
In our TextDocumentSyncHandler, which receives updates to all text files, we will have an instance of a TSParser to re-parse the files as they change and an instance of Analyzer to analyze the changed files.
public class TextDocumentSyncHandler : TextDocumentSyncHandlerBase
{
private readonly BufferManager bufManager;
private readonly ILanguageServerFacade languageServer;
private readonly TSParser parser; // newly added
private readonly Analyzer.Analyzer analyzer; // newly added
public TextDocumentSyncHandler(BufferManager manager,
ILanguageServerFacade languageServer)
{
bufManager = manager;
parser = new TSParser(TSJsonLanguage.Language()); // initialize with JSON language
this.languageServer = languageServer;
// initialize with an error query
analyzer = new Analyzer.Analyzer(new TSQuery(@"(ERROR) @error",
TSJsonLanguage.Language()));
}
// ...
}
@error next to our (ERROR) node in a TSQuery tells TreeSitter to put the information about (ERROR) node in that capture. Next we define a utility method to analyze buffers.
public class TextDocumentSyncHandler : TextDocumentSyncHandlerBase
{
// ...
private void AnalyzeWorkspace()
{
var diagnostics = analyzer.Analyze(bufManager.GetBuffers());
foreach (var buf in diagnostics)
{
languageServer.SendNotification(
new PublishDiagnosticsParams() { Uri = buf.Key,
Diagnostics = buf.Value.ToList() }
);
}
}
// ...
}Note that we need to publish the diagnostics for each file independently to the server. It would have been fine to analyze only a single opened or changed file and publish diagnostics but we are analyzing all the buffers here. This is fine as long as the performance is acceptable. Finally, we call this method whenever a new file is opened in the editor or an already open file changes.
public class TextDocumentSyncHandler : TextDocumentSyncHandlerBase
{
// ...
public override Task<Unit> Handle(
DidOpenTextDocumentParams request,
CancellationToken cancellationToken
)
{
bufManager.Add(request.TextDocument.Uri,
CreateBuffer(request.TextDocument.Text));
AnalyzeWorkspace(); // Analyze
return Unit.Task;
}
public override Task<Unit> Handle(
DidChangeTextDocumentParams request,
CancellationToken cancellationToken
)
{
var text = request.ContentChanges.FirstOrDefault()?.Text;
if (text is not null)
{
bufManager.Add(request.TextDocument.Uri, CreateBuffer(text));
AnalyzeWorkspace(); // Analyze
}
return Unit.Task;
}
// ...
}
Running this in VSCode will look like this. I have removed the comma on line 11. You can see that the first error is coming from armls, with VSCode also running its own analysis and reporting the errors.
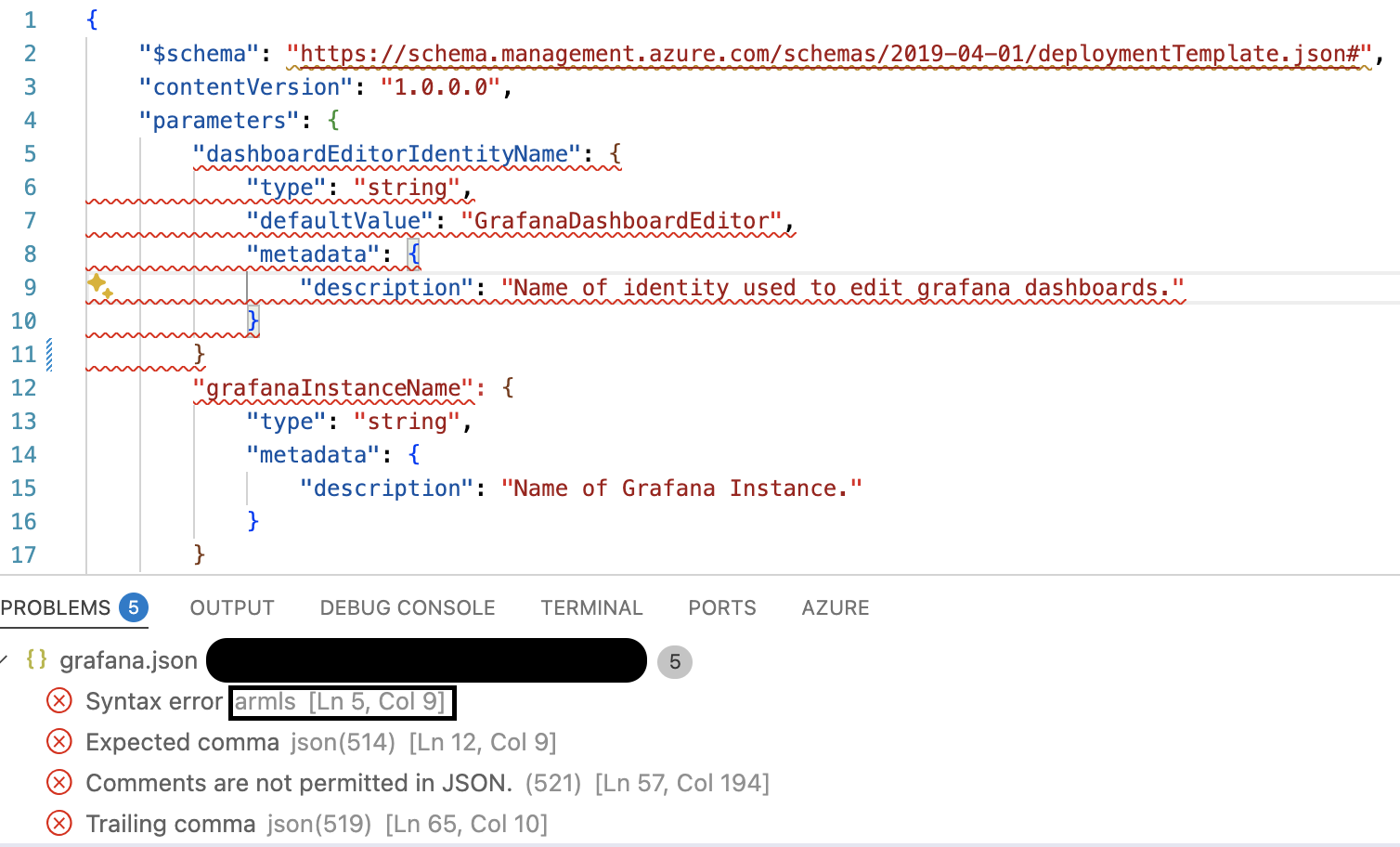
5. Conclusion
In this relatively long post, we learned many new concepts. In summary we learned to
- Create C# bindings for C library
- How to parse a block of text using a TreeSitter parser
- How to query a syntax tree and how to process the matches
- How to publish diagnostics to the editor/language client
Querying (ERROR) nodes from a tree does not cover all types of errors. More specifically, error nodes do not highlight locations where the parser was able to recover from the failure by adding a missing token. Those locations are marked with a (MISSING) node in the tree as described here. It will be a good exercise to implement support for missing nodes to this project. As I showed, it becomes very easy to work with the syntax trees once you have the TreeSitter bindings in place. In future posts, we will exercise our newfound power to walk the trees and extract information about nodes to implement richer editing experiences.