1. Introduction
In previous posts, we looked at an introduction to LSP and syntax checking using TreeSitter. This post will talk about using JSON Schema to check the schema of ARM templates. This post took longer than usual because of the challenges involved in taking the giant ARM template schema and making it usable for interactive scenarios.
2. JSON Schema
JSON schema is a structured way of describing the schema of a JSON file. It uses standard JSON format to describe the properties and their types. We can also encode a choice between multiple different types of values supported by a property by using oneOf or compose a value out of multiple different components by using allOf. A small example of a JSON schema might look like the following:
{
"$schema": "http://json-schema.org/draft-07/schema#",
"type": "object",
"required": ["$schema", "resources"],
"properties": {
"$schema": {
"type": "string"
},
"resources": {
"type": "array",
"items": {
"type": "object",
"required": ["type", "name"],
"properties": {
"type": { "type": "string" },
"name": { "type": "string" }
}
}
}
}
}
Among other things, this schema also says what properties are required to be specified. You can also refer to other schemas from a schema by using $ref and pointing to the schema through either a relative or an absolute path.
3. ARM Template Schema
Recent ARM templates refer to the latest ARM template schema defined in 2019, which is present at https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json. An abbreviated version of the schema file at that link looks like this:
{
"id": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#",
"$schema": "http://json-schema.org/draft-04/schema#",
"title": "Template",
"description": "An Azure deployment template",
"type": "object",
"properties": {
"$schema": {
"type": "string",
"description": "JSON schema reference"
},
// ...
"resource": {
"description": "Collection of resource schemas",
"oneOf": [
{
"allOf": [
{
"$ref": "#/definitions/resourceBase"
},
{
"oneOf": [
{
"$ref": "https://schema.management.azure.com/schemas/2017-08-01-preview/Microsoft.Genomics.json#/resourceDefinitions/accounts"
},
{
"$ref": "https://schema.management.azure.com/schemas/2016-06-01/Microsoft.RecoveryServices.legacy.json#/resourceDefinitions/vaults"
},
// Tons of other references
]
}
]
},
// ...
{
"$ref": "https://schema.management.azure.com/schemas/common/autogeneratedResources.json"
}
]
},
// ...
}
}
It describes the structure of various entities within ARM template like parameters, variables, functions, etc. The biggest section in the ARM template is the definition of a resource. The definition is just a ton of references to all the different resources and APIs defined by azure over the years. Given the scale of the functionalities provided by Azure, this section contains dozens upon dozens of references. Finally, it has a reference to common/autogeneratedResources.json which has references to even more resources. If you download the schemas for all of the supported resource types for all their API versions, you will have close to 50K schemas that weigh over 9GB! Reading and managing over 9GB of text will be an issue even in a batch processing system, let alone an interactive system like text editors. It was a big challenge for me to figure out how I can support schema checking at reasonable speeds with the data like that. I still went ahead and tried to work with this 9GB. Here are the things I tried.
3.1. Downloading the schemas
I decided to use JSON.Net Schema library for validating schema. It provides JSchemaUrlResolver which can automatically download schemas from the internet for all $ref references. At the time of trying this method, I didn't know that the entire suit of schema files is 9GB+. I gave the library the base deploymentTemplate schema and let it download all references off the internet. Over an hour passed but it couldn't finish downloading all schemas. This made me realize that there must be a huge number of schema files being referenced and the schema files might themselves be referencing other schema files. This was clearly not scalable.
3.2. Using azure-resource-manager-schemas
Azure has a public repository on GitHub at Azure/azure-resource-manager-schemas. This repository is supposed to contains the schemas for all resource providers on Azure. It also ships with a server that can locally serve all requests for https://schema.management.azure.com/schemas. This seemed promising. I cloned the repository and fired up the server. With the server running locally, the library was quickly able to pull a lot of schemas from the server within a few minutes. A few minutes of loading time for the language server is still pretty high but I was willing to work with it and optimize it later. It would be easy to either ship this server with the application or directly embed the schema files within the application. It might bloat the executable but it would've been fine for the purposes of this tutorial. However, I ran into issues even before getting there. Turns out that this repository is incomplete and does not have all schemas that are referred to within the web of references. I thought that it might be missing a few schemas that I can manually download and put in the local repository but even after downloading over a dozen schemas manually the library kept finding missing schemas. This was clearly not scalable.
3.3. Shipping Schemas
I still didn't know that the total size of the web of schemas was over 9GB. I was thinking more along the lines of a few or a few hundred MBs. At this point I turned to Claude. After some back and forth, Claude wrote me a script that will recursively download all $ref schemas starting with deploymentTemplate. After the script finished running, I looked at the size of the downloaded folder and was shocked to see the size as 9GB. I was still stupid enough to work with the size. I first tried loading the schemas from filesystem at runtime. The problem with Json.NET and possibly all other schema checking libraries is that they will load the entire referenced schema before they can validate the schema of the file, even though the file only refers to 3-5 resources out of thousands resources in the schema. It makes sense because the library cannot be sure without looking at the entire schema how many errors the file has, especially when there is a huge list of oneOf resources. But this creates an issue while trying to load the entire schema in memory. In trying to load all schemas off the disk the virtual memory of armls grew to over 40GB. Next I tried embedding all schemas within the executable itself. My MBP has 64GB of RAM so I thought loading a 9GB executable should at least be possible. Apart from the issue of compilation time of over 500 seconds, the process kept dying as soon as it was launched with OOM exception. This wasn't going to work.
The core issue is that existing tools try to validate against the entire universe of possible resources, when any given template only uses a handful. The solution, as we'll see, involves dynamically constructing a minimal, relevant schema on-the-fly for each template. This gives the validator just enough information to do its job without boiling the ocean.
3.4. Writing Your Own Schema
I only get to work on this project on weekend, and then too I'm not always in the mood to tackle such a difficult problem. So I kept thinking about the problem now and then. Even LLMs didn't help much. A potential solution finally struck me this weekend. The problem in this case was that the primary deploymentTemplate schema was referring to too many unnecessary schemas from all of Azure's lifetime. I just needed it to refer to half a dozen or less resources mentioned in any ARM template. This meant modifying the deploymentTemplate on-the-fly to only contain references to the resources mentioned in the ARM template. I decided to try this idea. I was so fed up from trying various solutions to this problem that I wasn't even willing to code this solution up. I fired up Claude Code and explained the idea to it. I gave it deploymentTemplate file as reference to find out which sections it needs to rewrite on-the-fly and which sections it needs to preserve. It wrote me a first draft. After prompting it to fix a few issues, the code worked. I was able to construct a minimal schema on-the-fly specifically for the resources mentioned in the file and use it to check the schema! Since the library needed only handful of schemas to verify any reasonably sized ARM template, I didn't even need to bundle any schema files with the executable. The library could just download it off the internet almost instantaneously.
4. Code Walkthrough
We will be working with the commit ID 569cfdd for this post. I've also added a bunch of corresponding changes to TreeSitter bindings which I won't be covering.
4.1. Buffer
We'll first add a method in Buffer to get the set of resources and their API versions defined in the template. These will be used to define the minimal schema for validation.
class Buffer
{
// Returns a dictionary mapping resource types to their API versions like {"Microsoft.Storage/storageAccounts": "2021-04-01"}.
public Dictionary<string, string> GetResourceTypes()
{
var resourceTypesWithVersions = new Dictionary<string, string>();
var query = new TSQuery(
@"(pair (string (string_content) @key) (array (object) @resource))",
TSJsonLanguage.Language()
);
var cursor = query.Execute(ConcreteTree.RootNode());
while (cursor.Next(out TSQueryMatch? match))
{
var captures = match!.Captures();
if (captures.Count >= 2 && captures[0].Text(Text).Equals("resources"))
{
var resourceNode = captures[1];
resourceTypesWithVersions[GetPropertyValue(resourceNode, "type")] =
GetPropertyValue(resourceNode, "apiVersion");
}
}
}
}4.2. MinimalSchemaComposer
We'll define a class to create the minimal schema for a template. We'll first have a schemaJsonCache to avoid downloading the base schema template repeatedly, an HttpClient to download base schema if it doesn't exist. I have the schemas downloaded locally which I'm going to use for loading but you can load the schemas from the internet as well. In my local schema cache, the files are named with GUIDs, so I maintain a schemaIndex which maps the schema URLs for various resources to their local file names.
public class MinimalSchemaComposer
{
private readonly Dictionary<string, string> schemaJsonCache;
private readonly HttpClient httpClient;
private readonly string schemaDirectory = "/Users/samvidmistry/Downloads/schemas";
private readonly Dictionary<string, string> schemaIndex;
public MinimalSchemaComposer()
{
schemaJsonCache = new();
httpClient = new();
var indexPath = Path.Combine(schemaDirectory, "schema_index.json");
var indexJson = File.ReadAllText(indexPath);
schemaIndex =
JsonConvert.DeserializeObject<Dictionary<string, string>>(indexJson)
?? new Dictionary<string, string>();
}
We then have the main function for composing the schema. We always want the common/definitions.json included because it contains the definitions for basic ARM primitives like an expression. We then construct URLs for all mentioned resources based on the pattern followed for Azure schemas. We also add the corresponding $ref entry in a JArray. This will be used to create the minimal schema with references to just the required resources. We then parallelly load the schemas for all referenced resources from the local disk. These can also be downloaded from the internet directly with a JSchemaURLResolver(). Finally, we call the utility function ConstructSchemaWithResources to construct the final schema.
public async Task<JSchema?> ComposeSchemaAsync(
string baseSchemaUrl,
Dictionary<string, string> resourceTypesWithVersions
)
{
if (!schemaJsonCache.TryGetValue(baseSchemaUrl, out var schemaJson))
{
schemaJson = await httpClient.GetStringAsync(baseSchemaUrl);
schemaJsonCache[baseSchemaUrl] = schemaJson;
}
// ... code to return if this is not a `deploymentTemplate`
var resolver = new JSchemaPreloadedResolver();
var resourceReferences = new JArray();
// Always load common definitions
var schemaUrls = new HashSet<string>
{
"https://schema.management.azure.com/schemas/common/definitions.json",
};
foreach (var (resourceType, apiVersion) in resourceTypesWithVersions)
{
var parts = resourceType.Split('/');
var provider = parts[0];
var resourceName = parts[1];
var schemaUrl =
$"https://schema.management.azure.com/schemas/{apiVersion}/{provider}.json";
schemaUrls.Add(schemaUrl);
resourceReferences.Add(
new JObject { ["$ref"] = $"{schemaUrl}#/resourceDefinitions/{resourceName}" }
);
}
(
await Task.WhenAll(
schemaUrls
.Where(url =>
schemaIndex.TryGetValue(url, out var filename)
&& File.Exists(Path.Combine(schemaDirectory, filename))
)
.Select(async url => new
{
Url = new Uri(url),
Content = await File.ReadAllTextAsync(
Path.Combine(schemaDirectory, schemaIndex[url])
),
})
)
)
.ToList()
.ForEach(s => resolver.Add(s.Url, s.Content));
return ConstructSchemaWithResources(schemaJson, resourceReferences) is { } minimalSchemaJson
? JSchema.Load(new JsonTextReader(new StringReader(minimalSchemaJson)), resolver)
: null;
}
This utility function finds the exact path where references to all thousands of schemas is embedded and replaces it with the minimal JArray that we created. It also replaces references to other schemas such as autogeneratedResources which is again a huge file with tons of references.
private string? ConstructSchemaWithResources(string baseSchemaJson, JArray resourceReferences)
{
try
{
var schemaObj = JObject.Parse(baseSchemaJson);
if (
schemaObj.SelectToken("definitions.resource.oneOf[0].allOf[1].oneOf")
is JArray resourceRefsArray
)
{
resourceRefsArray.Replace(resourceReferences);
}
if (
schemaObj.SelectToken("definitions.resource.oneOf") is JArray oneOfArray
&& oneOfArray.Any()
)
{
oneOfArray.ReplaceAll(oneOfArray.First());
}
return schemaObj.ToString();
}
catch (Exception)
{
// Return original schema if generation fails
return null;
}
}4.3. Analyzer
We will now update the Analyzer to check for schema. We will compose the minimal schema using MinimalSchemaComposer. Then use Json.NET Schema to verify the schema. For all errors we get, we will find the named parent that contains the location of the error and highlight that node with a warning. Named nodes in TreeSitter are nodes which have been given a dedicated name. These are generally the nodes that hold some semantic significance in the larger grammar. Json grammar has just 2, which are key and value. Json.NET Schema returns the errors in a tree shaped collection where it highlights errors from the smallest token that contains the error to the largest structure that nests the smaller token and every level in-between. However, we are only interested in leaf errors to highlight the smallest node that contains the error. So we have a utility function called GetLeafErrors that recursively processes the ValidationError objects to get the leaf nodes. We then find the closest named descendent for the token with error. It is useful to highlight the closest named structure instead of highlighting only the smallest token with the error because the writers of these files do not think at the level of tokens. They think at the level of entities, or in this case a single key or value, which make sense for the context. It is a good design to highlight the errors at the level of abstraction they are working with.
public async Task<IReadOnlyDictionary<string, IReadOnlyList<Diagnostic>>> AnalyzeAsync(
IReadOnlyDictionary<string, Buffer.Buffer> buffers
)
{
var diagnostics = new Dictionary<string, IReadOnlyList<Diagnostic>>();
foreach (var (path, buf) in buffers)
{
// ... check for syntax errors
// Extract resource types with their API versions from the ARM template
var resourceTypesWithVersions = buf.GetResourceTypes();
// Compose minimal schema with only needed resource definitions
var schema = await schemaComposer.ComposeSchemaAsync(
schemaUrl,
resourceTypesWithVersions
);
// ... handle the case where schema is null
IList<ValidationError> errors;
var isValid = JToken.Parse(buf.Text).IsValid(schema, out errors);
diagnostics[path] = GetLeafErrors(errors)
.Where(e => !e.Message.Contains("Expected Object but got Array."))
.Select(e => new Diagnostic
{
Range = buf
.ConcreteTree.RootNode()
.NamedDescendantForPointRange(
new TSPoint
{
row = (uint)e.LineNumber - 1,
column = (uint)e.LinePosition - 1,
},
new TSPoint
{
row = (uint)e.LineNumber - 1,
column = (uint)e.LinePosition - 1,
}
)
.GetRange(),
Message = e.Message,
Severity = DiagnosticSeverity.Warning,
})
.ToList();
}
return diagnostics;
}5. Conclusion
Once all of the pieces are implemented and connected, the schema errors will show up in your editor. Here's how it looks in VS Code.
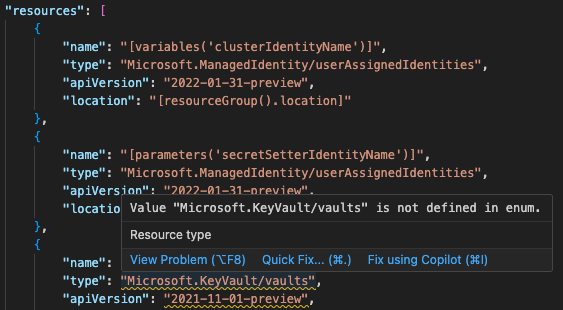
This post covered basics of how schema validation can be done for JSON files. This is by no means a production ready implementation, but given the complexities of validating the humongous schema web of ARM templates and the time I have on my hands, I feel this works good enough to get the point across. As we will see later, the schema files also provide us other information about the structures used in the file. In the next post, we'll see how to provide hover functionality using the schemas we just loaded.